- 注册时间
- 2008-7-21
- 最后登录
- 1970-1-1
- 威望
- 星
- 金币
- 枚
- 贡献
- 分
- 经验
- 点
- 鲜花
- 朵
- 魅力
- 点
- 上传
- 次
- 下载
- 次
- 积分
- 11565
- 在线时间
- 小时
|
楼主 |
发表于 2009-2-26 16:23:44
|
显示全部楼层
【快速排序代码模板】
【C】
排序一个整数的阵列- void swap(int *a, int *b)
- {
- int t=*a; *a=*b; *b=t;
- }
-
- void quicksort(int arr[],int beg,int end)
- {
- if (end >= beg + 1)
- {
- int piv = arr[beg], k = beg + 1, r = end;
-
- while (k < r)
- {
- if (arr[k] < piv)
- k++;
- else
- swap(&arr[k], &arr[r--]);
- }
- if (arr[k] < piv){
-
- swap(&arr[k],&arr[beg]);
-
- quicksort(arr, beg, k);
- quicksort(arr, r, end);
- }else {
- if (end - beg == 1)
- return;
-
- swap(&arr[--k],&arr[beg]);
- quicksort(arr, beg, k);
- quicksort(arr, r, end);
- }
- }
-
- }
-
- #include <functional>
- #include <algorithm>
- #include <iterator>
-
- template< typename BidirectionalIterator, typename Compare >
- void quick_sort( BidirectionalIterator first, BidirectionalIterator last, Compare cmp ) {
- if( first != last ) {
- BidirectionalIterator left = first;
- BidirectionalIterator right = last;
- BidirectionalIterator pivot = left++;
-
- while( left != right ) {
- if( cmp( *left, *pivot ) ) {
- ++left;
- } else {
- while( (left != right) && cmp( *pivot, *right ) )
- right--;
- std::iter_swap( left, right );
- }
- }
-
- if cmp( *pivot, *left )
- --left;
- std::iter_swap( first, left );
-
- quick_sort( first, left, cmp );
- quick_sort( right, last, cmp );
- }
- }
-
- template< typename BidirectionalIterator >
- inline void quick_sort( BidirectionalIterator first, BidirectionalIterator last ) {
- quick_sort( first, last,
- std::less_equal< typename std::iterator_traits< BidirectionalIterator >::value_type >()
- );
- }
-
- import java.util.Comparator;
- import java.util.Random;
-
- public class Quicksort {
- public static final Random RND = new Random();
-
- private void swap(Object[] array, int i, int j) {
- Object tmp = array[i];
- array[i] = array[j];
- array[j] = tmp;
- }
-
- private int partition(Object[] array, int begin, int end, Comparator cmp) {
- int index = begin + RND.nextInt(end - begin + 1);
- Object pivot = array[index];
- swap(array, index, end);
- for (int i = index = begin; i < end; ++ i) {
- if (cmp.compare(array[i], pivot) <= 0) {
- swap(array, index++, i);
- }
- }
- swap(array, index, end);
- return (index);
- }
-
- private void qsort(Object[] array, int begin, int end, Comparator cmp) {
- if (end > begin) {
- int index = partition(array, begin, end, cmp);
- qsort(array, begin, index - 1, cmp);
- qsort(array, index + 1, end, cmp);
- }
- }
-
- public void sort(Object[] array, Comparator cmp) {
- qsort(array, 0, array.length - 1, cmp);
- }
- }
- public static void Sort(int[] numbers)
- {
- Sort(numbers, 0, numbers.Length - 1);
- }
-
- private static void Sort(int[] numbers, int left, int right)
- {
- if (left < right)
- {
- int middle = numbers[(left + right) / 2];
- int i = left - 1;
- int j = right + 1;
- while (true)
- {
- while (numbers[++i] < middle) ;
-
- while (numbers[--j] > middle) ;
-
- if (i >= j)
- break;
-
- Swap(numbers, i, j);
- }
-
- Sort(numbers, left, i - 1);
- Sort(numbers, j + 1, right);
- }
- }
-
- private static void Swap(int[] numbers, int i, int j)
- {
- int number = numbers[i];
- numbers[i] = numbers[j];
- numbers[j] = number;
- }
-
|
|

 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2009-2-26 15:38:16
发表于 2009-2-26 15:38:16

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡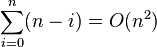 T(n) = O(n) + T(1) + T(n - 1) = O(n) + T(n - 1)
这与插入排序和选择排序有相同的关系式,以及它被解为T(n) = Θ(n2)。
【乱数快速排序的期望复杂度】
不管输入怎样下,乱数快速排序拥有得当的特性,也就是它只需要O(n log n)期望的时间。是什么让随机的基准变成一个好的选择?
假设我们排序一个数列,然后把它分为四个部份。在中央的两个部份将会包含最好的基准值;他们的每一个至少都会比25%的元素大,且至少比25%的元素小。如果我们可以一致地从这两个中央的部份选出一个元素,在到达大小为1的数列前,我们可能最多仅需要把数列分割2log2 n次,产生一个 O(nlogn)算法。
不幸地,乱数选择只有一半的时间会从中间的部份选择。出人意外的事实是这样就已经足够好了。想像你正在翻转一枚硬币,一直翻转一直到有 k 次人头那面出现。尽管这需要很长的时间,平均来说只需要 2k 次翻动。且在 100k 次翻动中得到 k 次人头那面的机会,是像天文数字一样的非常小。借由同样的论证,快速排序的递回平均只要2(2log2 n)的呼叫深度就会终止。但是如果它的平均呼叫深度是O(log n)且每一阶的呼叫树状过程最多有 n 个元素,则全部完成的工作量平均上是乘积,也就是 O(n log n)。
【平均复杂度】
即使如果我们无法随机地选择基准数值,对于它的输入之所有可能排列,快速排序仍然只需要O(n log n)时间。因为这个平均是简单地将输入之所有可能排列的时间加总起来,除以n这个因子,相当于从输入之中选择一个随机的排列。当我们这样作,基准值本质上就是随机的,导致这个算法与乱数快速排序有一样的执行时间。
更精确地说,对于输入顺序之所有排列情形的平均比较次数,可以借由解出这个递回关系式可以精确地算出来。
T(n) = O(n) + T(1) + T(n - 1) = O(n) + T(n - 1)
这与插入排序和选择排序有相同的关系式,以及它被解为T(n) = Θ(n2)。
【乱数快速排序的期望复杂度】
不管输入怎样下,乱数快速排序拥有得当的特性,也就是它只需要O(n log n)期望的时间。是什么让随机的基准变成一个好的选择?
假设我们排序一个数列,然后把它分为四个部份。在中央的两个部份将会包含最好的基准值;他们的每一个至少都会比25%的元素大,且至少比25%的元素小。如果我们可以一致地从这两个中央的部份选出一个元素,在到达大小为1的数列前,我们可能最多仅需要把数列分割2log2 n次,产生一个 O(nlogn)算法。
不幸地,乱数选择只有一半的时间会从中间的部份选择。出人意外的事实是这样就已经足够好了。想像你正在翻转一枚硬币,一直翻转一直到有 k 次人头那面出现。尽管这需要很长的时间,平均来说只需要 2k 次翻动。且在 100k 次翻动中得到 k 次人头那面的机会,是像天文数字一样的非常小。借由同样的论证,快速排序的递回平均只要2(2log2 n)的呼叫深度就会终止。但是如果它的平均呼叫深度是O(log n)且每一阶的呼叫树状过程最多有 n 个元素,则全部完成的工作量平均上是乘积,也就是 O(n log n)。
【平均复杂度】
即使如果我们无法随机地选择基准数值,对于它的输入之所有可能排列,快速排序仍然只需要O(n log n)时间。因为这个平均是简单地将输入之所有可能排列的时间加总起来,除以n这个因子,相当于从输入之中选择一个随机的排列。当我们这样作,基准值本质上就是随机的,导致这个算法与乱数快速排序有一样的执行时间。
更精确地说,对于输入顺序之所有排列情形的平均比较次数,可以借由解出这个递回关系式可以精确地算出来。
 在这里,n-1 是分割所使用的比较次数。因为基准值是相当均匀地落在排列好的数列次序之任何地方,总和就是所有可能分割的平均。
这个意思是,平均上快速排序比理想的比较次数,也就是最好情况下,只大约比较糟39%。这意味着,它比最坏情况较接近最好情况。这个快速的平均执行时间,是快速排序比其他排序算法有实际的优势之另一个原因。
【空间复杂度】
被快速排序所使用的空间,依照使用的版本而定。使用原地(in-place)分割的快速排序版本,在任何递回呼叫前,仅会使用固定的額外空間。然而,如果需要产生O(log n)巢状递回呼叫,它需要在他们每一个储存一个固定数量的资讯。因为最好的情况最多需要O(log n)次的巢状递回呼叫,所以它需要O(log n)的空间。最坏情况下需要O(n)次巢状递回呼叫,因此需要O(n)的空间。
然而我们在这里省略一些小的细节。如果我们考虑排序任意很长的数列,我们必须要记住我们的变量像是left和right,不再被认为是占据固定的空间;也需要O(log n)对原来一个n项的数列作索引。因为我们在每一个堆栈框架中都有像这些的变量,实际上快速排序在最好跟平均的情况下,需要O(log2 n)空间的位元数,以及最坏情况下O(n log n)的空间。然而,这并不会太可怕,因为如果一个数列大部份都是不同的元素,那么数列本身也会占据O(n log n)的空间字节。
非原地版本的快速排序,在它的任何递回呼叫前需要使用O(n)空间。在最好的情况下,它的空间仍然限制在O(n),因为递回的每一阶中,使用与上一次所使用最多空间的一半,且
在这里,n-1 是分割所使用的比较次数。因为基准值是相当均匀地落在排列好的数列次序之任何地方,总和就是所有可能分割的平均。
这个意思是,平均上快速排序比理想的比较次数,也就是最好情况下,只大约比较糟39%。这意味着,它比最坏情况较接近最好情况。这个快速的平均执行时间,是快速排序比其他排序算法有实际的优势之另一个原因。
【空间复杂度】
被快速排序所使用的空间,依照使用的版本而定。使用原地(in-place)分割的快速排序版本,在任何递回呼叫前,仅会使用固定的額外空間。然而,如果需要产生O(log n)巢状递回呼叫,它需要在他们每一个储存一个固定数量的资讯。因为最好的情况最多需要O(log n)次的巢状递回呼叫,所以它需要O(log n)的空间。最坏情况下需要O(n)次巢状递回呼叫,因此需要O(n)的空间。
然而我们在这里省略一些小的细节。如果我们考虑排序任意很长的数列,我们必须要记住我们的变量像是left和right,不再被认为是占据固定的空间;也需要O(log n)对原来一个n项的数列作索引。因为我们在每一个堆栈框架中都有像这些的变量,实际上快速排序在最好跟平均的情况下,需要O(log2 n)空间的位元数,以及最坏情况下O(n log n)的空间。然而,这并不会太可怕,因为如果一个数列大部份都是不同的元素,那么数列本身也会占据O(n log n)的空间字节。
非原地版本的快速排序,在它的任何递回呼叫前需要使用O(n)空间。在最好的情况下,它的空间仍然限制在O(n),因为递回的每一阶中,使用与上一次所使用最多空间的一半,且
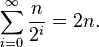 它的最坏情况是很恐怖的,需要
它的最坏情况是很恐怖的,需要
 空间,远比数列本身还多。如果这些数列元素本身自己不是固定的大小,这个问题会变得更大;举例来说,如果数列元素的大部份都是不同的,每一个将会需要大约O(log n)为原来储存,导致最好情况是O(n log n)和最坏情况是O(n2 log n)的空间需求。
【选择的关连性】
选择算法(selection algorithm)可以选取一个数列的第k个最小值;一般而言这是比排序还简单的问题。一个简单但是有效率的选择算法与快速排序的作法相当类似,除了对两个子数列都作递回呼叫外,它仅仅针对包含想要的元素之子数列作单一的结尾递回(tail recursive)呼叫。这个小改变降低了平均复杂度到线性或是Θ(n)时间,且让它成为一个原地算法。这个算法的一种变化版本,可已让最坏情况下降为O(n)(参考选择算法来得到更多资讯)。
相反地,一旦我们知道一个最坏情况的O(n)选择算法是可以利用的,我们在快速排序的每一步可以用它来找到理想的基准(中位数),得到一种最化情况下O(n log n)执行时间的变化版本。在实际的实作,然而这种版本一般而言相当的慢。
【代码模板】见楼下
空间,远比数列本身还多。如果这些数列元素本身自己不是固定的大小,这个问题会变得更大;举例来说,如果数列元素的大部份都是不同的,每一个将会需要大约O(log n)为原来储存,导致最好情况是O(n log n)和最坏情况是O(n2 log n)的空间需求。
【选择的关连性】
选择算法(selection algorithm)可以选取一个数列的第k个最小值;一般而言这是比排序还简单的问题。一个简单但是有效率的选择算法与快速排序的作法相当类似,除了对两个子数列都作递回呼叫外,它仅仅针对包含想要的元素之子数列作单一的结尾递回(tail recursive)呼叫。这个小改变降低了平均复杂度到线性或是Θ(n)时间,且让它成为一个原地算法。这个算法的一种变化版本,可已让最坏情况下降为O(n)(参考选择算法来得到更多资讯)。
相反地,一旦我们知道一个最坏情况的O(n)选择算法是可以利用的,我们在快速排序的每一步可以用它来找到理想的基准(中位数),得到一种最化情况下O(n log n)执行时间的变化版本。在实际的实作,然而这种版本一般而言相当的慢。
【代码模板】见楼下