- 注册时间
- 2007-12-28
- 最后登录
- 1970-1-1
- 威望
- 星
- 金币
- 枚
- 贡献
- 分
- 经验
- 点
- 鲜花
- 朵
- 魅力
- 点
- 上传
- 次
- 下载
- 次
- 积分
- 12787
- 在线时间
- 小时
|
 发表于 2008-3-25 17:19:08
|
显示全部楼层
发表于 2008-3-25 17:19:08
|
显示全部楼层
我曾在我的csdn博客的一篇文章中讲过 IEE754的浮点数格式,见 阶乘之计算从入门到精通-近似计算之一 - liangbch的专栏 - CSDNBlog. 下面摘录 其中的关于浮点数格式的部分 内容如下:
浮点数主要分为32bit单精度和64bit双精度两种。本方只讨论64bit双精度(double型)浮点数的格式,一个double型浮点数包括8个字节(64bit),我们把最低位记作bit0,最高位记作bit63,则一个浮点数各个部分定义为:第一部分尾数:bit0至bit51,共计52bit,第二部分阶码:bit52-bit62,共计11bit,第三部分符号位:bit63,0:表示正数,1表示负数。如一个数为0.xxxx * 2^ exp,则exp表示指数部分,范围为-1023到1024,实际存储时采用移码的表示法,即将exp的值加上0x3ff,使其变为一个0到2047范围内的一个值。函数GetExpBase2 中各语句含义如下:1.“(*pWord & 0x7fff)”,得到一个bit48-bit63这个16bit数,最高位清0。2.“>>4”,将其右移4位以清除最低位的4bit尾数,变成一个11bit的数(最高位5位为零)。3.“(rank-0x3ff)”, 减去0x3ff还原成真实的指数部分。以下为完整的代码。- #include "stdafx.h"
- #include "math.h"
-
- #define MAX_N 10000000.00 //能够计算的最大的n值,如果你想计算更大的数对数,可将其改为更大的值
- #define MAX_MANTISSA (1e308/MAX_N) //最大尾数
- typedef unsigned short WORD;
-
- struct bigNum
- {
- double n1; //表示尾数部分
- int n2; //表示阶码部分
- };
-
- short GetExpBase2(double a) // 获得 a 的阶码
- {
- // 按照IEEE 754浮点数格式,取得阶码,仅仅适用于Intel 系列 cpu
- WORD *pWord=(WORD *)(&a)+3;
- WORD rank = ( (*pWord & 0x7fff) >>4 );
- return (short)(rank-0x3ff);
- }
-
- double GetMantissa(double a) // 获得 a 的 尾数
- {
- // 按照IEEE 754浮点数格式,取得尾数,仅仅适用于Intel 系列 cpu
- WORD *pWord=(WORD *)(&a)+3;
- *pWord &= 0x800f; //清除阶码
- *pWord |= 0x3ff0; //重置阶码
- return a;
- }
|
|

 IP卡
IP卡 狗仔卡
狗仔卡
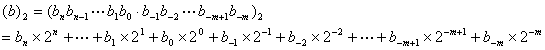 例4:
例4: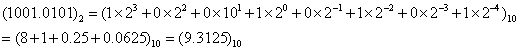 二进制数转换成十进制数,比较容易,如例4。 十进制数转换成二进制数,是把整数部分和小数部分分别转换,整数部分用2除,取余数,小数部分用2乘,取整数位。
例5:把(13.125)10转换成二进制数 整数部分:
二进制数转换成十进制数,比较容易,如例4。 十进制数转换成二进制数,是把整数部分和小数部分分别转换,整数部分用2除,取余数,小数部分用2乘,取整数位。
例5:把(13.125)10转换成二进制数 整数部分: 因此,
因此, 得到一个无限循环的二进制小数
得到一个无限循环的二进制小数 也无法用IEEE 754浮点数精确表示。
结论1:
也无法用IEEE 754浮点数精确表示。
结论1: 可以一直算下去,得到一个基本规律
结论3:一个十进制小数要能用浮点数精确表示,最后一位必须是5,因为1 除以2永远是0.5,当然这是必要条件,并非充分条件。 一个m位二进制小数能够精确表示的十进制小数有多少个呢?当然是
可以一直算下去,得到一个基本规律
结论3:一个十进制小数要能用浮点数精确表示,最后一位必须是5,因为1 除以2永远是0.5,当然这是必要条件,并非充分条件。 一个m位二进制小数能够精确表示的十进制小数有多少个呢?当然是 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡